
With the increased need for redundancy and fault tolerance in distributed computing a 40 years old question is more in focus than ever: how to build a self-replicating distributed fault tolerant system?
Do we have a consensus?
Let's say, for the sake of an argument, that you've been appointed a task of creating the fault-tolerant system. Your data is being collected by a number of network agents and you need to process and store that data. Processing should be done on your 'back end' (BE) application. Your BE application is a state machine which processes and store data collected from network agents.
Making system fault-tolerant cannot be that hard, right? Add a few more machines to the system, if possible more than two, as we cannot end up with only one of them running if one node fails. Install the BE application on them and with some peace of middleware make all data replicable from one node to other nodes creating a fault-tolerant system. Voila!
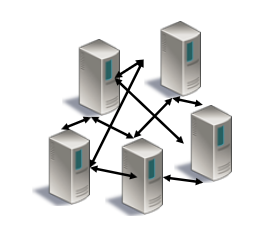
So far, so good. As it turns out, we will need a specialized part of the software (middleware) to take care and handle the data replication part. How this piece of middleware works? How can we guarantee that the same piece of data inserted as an input into our state machine produces the same result on all the other nodes? All nodes have the same application, hence the same state machine. How can we distribute the same data across all the nodes and keep the state machines in sync across all the nodes? Good question.
Having more nodes connected by some network infrastructure means that we have an asynchronous distributed system. By very nature, real-world distributed systems should not make any strong assumptions about time and order of events. That means that simply pushing the data from one node to another can end up in out of order receive or we can even end up without receive at all. Computer networks are notoriously unreliable. Can we detect that network has failed? How do we know that for sure? Obviously, we cannot just push data from one node to all the other nodes. We need some feedback from nodes when pushing values to them. What if one of the nodes fail?
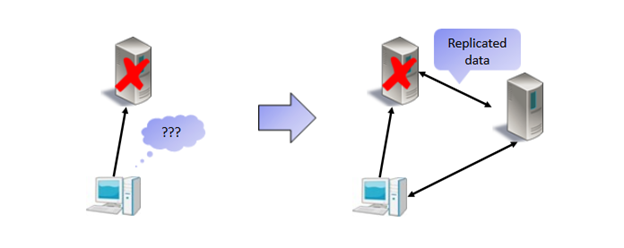
Some of the nodes would probably be pretty easy out of sync when some of them fail. Fault-tolerant systems must have some mechanism for detecting failures; simply because the system needs a way to report which nodes are in good health and can be accounted for replication and which are not. In the end, we are building a fault-tolerant system which must make progress in time and cannot be halted by some faulty process on some of the nodes we are replicating data to. The end goal is that all the state machines on all the nodes have the same data (same processing result).
Brief history of consensus algorithms
It looks like solving our fault-tolerance problem is not that easy task after all. It is one big ongoing research (and debate!) from 1960’s where first concurrent operating systems (and distributed systems) were studied. The study of distributed computing became its branch of computer science in the late 1970s and early 1980s. The above-mentioned problem, in particular, is very well known as a “distributed consensus problem”.
One of the most important results in distributed systems theory was published in April 1985 by Fischer, Lynch and Patterson. Their short paper Impossibility of Distributed Consensus with One Faulty Process (which won the Dijkstra award as one of the most influential papers in distributed computing) definitively placed an end to the ongoing discussion and upper bound on what it is possible to achieve with distributed processes in an asynchronous environment. Their particular result known as the FLP result settled a dispute that had been ongoing in distributed systems for the previous ten years. The problem of consensus – getting a distributed network of nodes to agree on a standard value - was known to be solvable in a contemporary setting, where nodes could proceed in simultaneous steps. The synchronous solution was resilient to faults, where nodes crash and take no further part in the computation. Synchronous models allow failures to be detected by waiting for one entire step length for a reply from a node, and presuming that it has crashed if no response is received.
This kind of failure detection is impossible in an asynchronous setting where there are no bounds on the amount of time a node might take to complete its work and then respond with a message (significant network lag). Therefore it’s not possible to say whether a node is simply taking a long time to respond or has crashed. The FLP result shows that in an asynchronous setting - where only one node might crash - there is no distributed algorithm which solves the consensus problem.
However, we nowadays have distributed systems which work and employ different consensus algorithms. Follow up paper by Ben-Or showed that with a randomized algorithm, it was possible to solve the problem even with a constant fraction of bad nodes, albeit in exponential time. This was a fundamental result which gives some idea of how useful randomization can be for computation under an adversarial model. Early randomized algorithms for consensus like Ben-Or’s used very clever tricks, but no heavy duty mathematical machinery. More recent results, which run in polynomial time, make use of more modern tricks like the probabilistic method, expanders, extractors, samplers and connections with error-correcting codes, along with different cryptographic tricks. No completely asynchronous consensus protocol can tolerate even a single unannounced node death using a deterministic algorithm, but today we use probabilistic solutions for this problem which guarantees that as long as a majority of the nodes continues to operate, a decision will be made and the system will continue to operate. A consensus is not “impossible”; it is just “not always possible”.
Distributed consensus
Distributed consensus is fundamental to building fault-tolerant systems. Distributed consensus algorithm allows a collection of nodes to work as a coherent group that can survive the failures of some of its members. The basic idea behind a consensus algorithm is that n node each vote on a proposed value, and at the end of voting, nodes must have a consensus about a suggested value. We may say that nodes want to hold an election to decide if value proposed by one of the nodes wins the election. To work as a coherent group, nodes must have some way to agree upon a value suggested by one of the nodes in the group. We can say that the suggested value is chosen if in a group of n nodes at least n/2+1 nodes accept the suggested value so a majority of nodes must accept the value - in a five nodes group at least three nodes must accept the suggested value. That majority is often referred as a Quorum. Group of nodes can make progress while having at least quorum to agree upon a suggested value. Without a quorum distributed consensus system cannot make progress. As any node can suggest a value, the problem is made more interesting by the fact that there may be no leader, i.e. no single node who other nodes know that is trustworthy and can be counted on to tabulate all the votes accurately (today's most used consensus algorithms are mostly leader based though).
Several papers in the literature set the problem in the context of Byzantine generals at different camps outside the big enemy castle deciding whether or not to attack. Generals must exchange notes about their decision - attack or not attack – but how do they know if one of them is not lying or that message exchanged is not corrupted along the way? A consensus algorithm that didn’t work would perhaps cause one general to attack while all the others stayed back – leaving the first general in trouble. As we see, some of the nodes in the consensus group can even lie about their values to other nodes in the group. Translated into machine language, nodes can be in the faulty state producing or reporting incorrect values/results (referred as Byzantine Faults). Some consensus algorithms today's account for a Byzantine behaviour and that kind of algorithm is known as a Byzantine Fault Tolerant (BFT) algorithm.
To conclude first blog post in this series, consensus algorithms are widely regarded as difficult to understand and implement correctly. In the presence of BFT, they are even harder. There are consensus algorithms specifically designed to address the BFT problem, but ones mostly used today do not address this problem (they are designed for fail-stop situations, not for nodes which lie about their state). In the next blog post in this series, we will see the consequences of the FLP result and two of today's probably most used consensus algorithms, so stay tuned!
